-
O efeito ChatGPT baseado em Inteligência Artificial e o ensino nas Universidades

Um recente artigo publicado no jornal The New York Times chamou a atenção dos leitores para um fato irrefutável: o uso de ferramentas baseadas em Inteligência Artificial que criam textos via máquina está ganhando espaço nas escolas e universidades, levando-as a reestruturar seus cursos de escrita e a tomar medidas preventivas contra a possibilidade de plágio em massa.
Esta matéria é uma compilação de Elisabeth Dudziak de informações embasadas em textos sobre o chamado “efeito ChatGPT” e de outras ferramentas baseadas em inteligência artificial e como as universidades estão sendo levadas a mudar seus métodos de ensino e verificação de textos. Em síntese, abordamos o fato de que as ferramentas baseadas em Inteligência Artificial (IA) estão mudando o modo como a redação e a escrita são realizadas e ensinadas nas escolas e universidades.
O relato de um professor esclarece a surpresa que teve ao deparar-se com um trabalho de ótima qualidade: “enquanto corrigia redações para seu curso de religiões mundiais, Antony Aumann, professor de filosofia na Universidade do Norte de Michigan, leu uma que ele disse ser “a melhor redação da classe”. Instantaneamente, um alarme disparou em sua cabeça. Aumann confrontou seu aluno para descobrir se ele havia escrito a redação. O aluno confessou ter utilizado o ChatGPT, um bot conversacional que fornece informação, explica conceitos e gera ideias em frases simples… e, neste caso, tinha escrito o paper.” [1].

O ChatGPT é um desses exemplos de modelos baseados em IA que interage de forma conversacional e esse formato de diálogo permite que o ChatGPT responda a perguntas de acompanhamento, admita seus erros, conteste premissas incorretas e rejeite solicitações inadequadas. O ChatGPT é um modelo irmão do InstructGPT , que é treinado para seguir uma instrução em um prompt e fornecer uma resposta detalhada. De acordo com seus mantenedores, o ChatGPT interage de forma conversacional. O formato de diálogo permite que o ChatGPT responda a perguntas de acompanhamento, admita seus erros, conteste premissas incorretas e rejeite solicitações inadequadas.
Paralelamente, o Google criou o LaMDA , um chatbot rival, e a Microsoft está considerando um investimento de US$ 10 bilhões na OpenAI que acaba de incorporar o ChatGPT. Outras empresas do Vale do Silício também estão que estão trabalhando em ferramentas generativas de inteligência artificial [1].
Ainda de acordo com a matéria publicada no jornal The New York Times [1], o professor “Aumann ficou alarmado com sua descoberta, então decidiu transformar a redação de seus cursos neste semestre. Ele planeja exigir que eles escrevam os primeiros rascunhos na sala de aula, usando navegadores que monitoram e restringem a atividade do computador. Em rascunhos subsequentes, os alunos precisarão explicar cada correção. Aumann, que pode parar de pedir redações nos próximos semestres, também planeja integrar o ChatGPT às aulas, onde pedirá aos alunos que avaliem as respostas do chatbot. “Nas aulas, a dinâmica não será mais assim: ‘Aqui estão algumas perguntas e vamos conversar sobre isso entre nós como seres humanos’”, disse ele, mas “será assim: ‘O que é isso…robô alienígena pensando também?’” .
Em muitas universidades no mundo e seus professores, pesquisadores e administradores estão preocupados com a disponibilidades dessas ferramentas e o impacto na escrita científica e acadêmica. Diversas instituições de ensino e pesquisa estão começando a remodelar as atividades em salas de aula em resposta ao ChatGPT , “o que pode desencadear uma grande mudança no ensino e na aprendizagem. Alguns professores estão reformulando completamente seus cursos, fazendo mudanças como mais exames orais, trabalhos em grupo e avaliações manuscritas em vez de digitadas. As iniciativas fazem parte de uma luta em tempo real contra uma nova onda de tecnologia conhecida como inteligência artificial generativa ” [1]
Também segundo a matéria, “… a George Washington University em Washington DC, a Rutgers University em New Brunswick, New Jersey e a Appalachian State University em Boone, Carolina do Norte, os professores estão eliminando gradualmente os deveres de casa e o livro aberto, que se tornou um método dominante de avaliação na pandemia. mas agora parecem vulneráveis a chatbots. Em vez disso, eles estão optando por tarefas em sala de aula, ensaios manuscritos, trabalhos em grupo e exames orais.” [1]. Outras universidades estão elaborando revisões em suas políticas de integridade acadêmica para que suas definições de plágio incluam inteligência artificial generativa.
É necessário iniciar as discussões sobre o uso de ferramentas de inteligência artificial generativa como a ChatGPT em cursos que ensinam aos estudantes universitários conceitos como integridade, ética e escrita.
O uso indevido de ferramentas de inteligência artificial provavelmente não terminará, então alguns professores e universidades disseram que planejam usar detectores para acabar com essa atividade. O serviço de detecção de plágio Turnitin disse que estava adicionando mais recursos para identificar a inteligência artificial este ano, incluindo o ChatGPT [2].

Fonte: https://www.turnitin.com/blog/sneak-preview-of-turnitins-ai-writing-and-chatgpt-detection-capability
Segundo a equipe Turnitin, empresa especializada na verificação de similaridade de textos, ” em um matéria anterior intitulada Escrita de IA: o desafio e a oportunidade diante da educação agora , exploramos as maneiras pelas quais nosso Índice de Similaridade não é, de fato, um índice de plágio. Em vez disso, é uma ferramenta muito maior destinada a apoiar os resultados de aprendizagem do aluno, oferecendo dados objetivos que os educadores podem usar em seu fluxo de trabalho para informar seu ensino abrangente e a compreensão dos alunos sobre integridade acadêmica. As ferramentas do Turnitin como um todo são projetadas para fornecer contexto e informações a instrutores e administradores para que possam tomar decisões melhores e mais informadas. Há uma distinção significativa entre integridade acadêmica e plágio . ” [2]
De fato, em um mundo onde o rápido desenvolvimento de ferramentas de Inteligência Artificial (IA) está obscurecendo as próprias linhas que usamos para definir o trabalho original, é crucial ressaltarmos a importância da integridade acadêmica e discernir como a IA desempenhará um papel na educação. tecnologia, inovação e sim, plágio nos próximos anos. Queremos garantir que nossos produtos e serviços ajudem os educadores a economizar tempo, fornecer feedback melhor e ajudar os alunos a aprender mais. Esta é uma pergunta difícil, mas estamos prontos para o desafio. Continuamos a investir em nossa equipe de cientistas de dados, engenheiros e gerentes de produto que estão construindo a próxima geração de produtos e recursos Turnitin.” [3].
Mais de 6.000 professores das universidades de Harvard, Yale e Rhode Island, entre outras, também se inscreveram para usar o GPTZero, um programa que promete detectar rapidamente textos gerados por IA, disse Edward Tian, seu criador [1]. Também recebemos a informação sobre a existência de outra ferramenta denominada Cross Plag .
Frases repetitivas, palavras incomuns na redação dos alunos, redação qualificada demais e não usual aos estudantes. Outro ponto é que, se você é professor e está corrigindo várias tarefas que têm a mesma construção ou os mesmos exemplos ou raciocínio, então pode ser um texto gerado por IA. Além disso, o ChatGPT é treinado em dados desatualizados, anteriores a 2021 ou 2022 e, portanto, não será capaz de detectar algo que aconteceu recentemente [4]

Fonte: https://gptzero.me/
De acordo com Wang, em matéria intitulada Como é o plágio em um mundo com inteligência artificial? [3], “dez anos atrás, não existiam serviços de paráfrase de IA semelhantes aos humanos, nem serviços terceirizados de redação de contratos e respostas a perguntas. Nos últimos 24 meses, vimos o surgimento de poderosas arquiteturas de IA que podem transmitir níveis notáveis de compreensão e intuição por meio da geração e manipulação de escrita e imagens. Crucialmente, essas tecnologias existem não como curiosidades de pesquisa, mas como produtos comercialmente viáveis que já estão sendo usados pelo público em geral. Essas tecnologias significam que as decisões de integridade acadêmica que os instrutores e administradores confiaram no Turnitin para ajudá-los a tomar repentinamente ordens de magnitude mais complexas.”
A mídia brasileira já tem abordado o movimento viral do chatbot ChatGPT e os investimentos que a Microsoft tem feito na área. São exemplos a matéria publicada no jornal O Estado de São Paulo , O Globo e Folha de São Paulo, com foco na área de investimentos. Há também a matéria de opinião intitulada ChatGPT deve dar motivação e não preguiça, publicada ontem no jornal Folha de São Paulo. Entre outras, a matéria Cérebro eletrônico, também da Folha de São Paulo, busca as potencialidades da inteligência artificial “que pode liberar as mentes humanas para uma série de tarefas mais criativas.”. Também refere-se a aplicações promissoras que envolvem a elaboração de diagnósticos e relatórios médicos, pareceres jurídicos, correção de softwares, etc.
Fonte: https://www.pressreader.com/brazil/folha-de-s-paulo/20230124/textview
Entretanto, a questão central nos parece ser como podemos tirar proveito dessas ferramentas sem comprometer a qualidade do ensino e da pesquisa nas escolas e universidades?
O caminho na Universidade de São Paulo já tem uma direção e ela passa pela formação dos estudantes com ênfase na ética e na integridade, investimento no aprimoramento da escrita e redação científica e acadêmica, ampliação do uso de plataformas de prevenção de plágio como o Turnitin por docentes em conjunto com as bibliotecas, em benefício dos estudantes e pesquisadores, além da adoção de ferramentas como o Crossref Similarity Check iThenticate , destinado à identificação de similaridade de textos em artigos e itens publicados em Revistas da Universidade. Ambas as ferramentas são assinadas pela USP desde 2016 por meio da Agência de Bibliotecas e Coleções Digitais (ABCD-USP).
== REFERÊNCIAS ==
[1] HUANG, Kalley. El efecto ChatGPT: las universidades cambian sus métodos de enseñanza. The New York Times, 18 enero 2023.
[2] CHECHITELLI, Annie. Sneak preview of Turnitin’s AI writing and ChatGPT detection capability. Turnitin Blog, Jan. 13, 2023. Disponível em: https://www.turnitin.com/blog/sneak-preview-of-turnitins-ai-writing-and-chatgpt-detection-capability Acesso em 24 jan. 2023.
[3] WANG, Eric. What does plagiarism look like in a world with artificial intelligence? Turnitin Blog, 12 Oct. 2022. Disponível em: https://www.turnitin.com/blog/what-does-plagiarism-look-like-in-a-world-with-artificial-intelligence Acesso em: 24 jan. 2023.
[4] KHATSENKOVA, Sophia. ChatGPT: Is it possible to detect AI-generated text? Euronews, Jan 19th, 2023. Disponível em: https://www.euronews.com/next/2023/01/19/chatgpt-is-it-possible-to-detect-ai-generated-text Acesso em: 24 jan. 2023.
Como citar esta matéria:
DUDZIAK, Elisabeth Adriana. O efeito ChatGPT baseado em Inteligência Artificial e o ensino nas Universidades. Portal ABCD, jan. 2023. Disponível em: https://www.abcd.usp.br/noticias/ia-e-o-ensino-nas-universidades/ Acesso em: …
-
Medindo os impactos dos metadados: capacidade de descoberta de livros no Google Scholar

A comunidade de publicação acadêmica fala MUITO sobre metadados e a necessidade de descritores de alta qualidade, interoperáveis e legíveis por máquina do conteúdo que disseminamos. No entanto, como anteriormente refletido no The Scholarly Kitchen , apesar dos padrões de informação bem estabelecidos (por exemplo, identificadores persistentes), o setor carece de uma estrutura compartilhada para medir o valor e o impacto dos metadados que são produzidos.
Esta é uma tradução livre da matéria publicada no Blog The Scholarly Kitchen intitulada Measuring Metadata Impacts: Books Discoverability in Google Scholar [1].
Em 2021, embarcamos em um estudo patrocinado pela Crossref projetado para medir como os metadados afetam as experiências do usuário final e contribuem para a descoberta bem-sucedida de literatura acadêmica e de pesquisa por meio da web convencional. Especificamente, procuramos saber se livros acadêmicos com DOIs (e metadados associados) eram mais facilmente encontrados no Google Scholar do que aqueles sem DOIs.
Os resultados iniciais indicaram que os DOIs têm uma influência indireta na capacidade de descoberta de livros acadêmicos no Google Scholar – no entanto, não encontramos nenhuma ligação direta entre os DOIs de livros e a qualidade da indexação do Google Scholar ou a capacidade dos usuários de acessar o texto completo por meio de links de resultados de pesquisa . Embora o Google Scholar afirme não usar metadados DOI em seu índice de pesquisa, os resultados de nosso estudo de métodos mistos de mais de 100 livros (de 20 editoras) demonstram que livros com DOIs são geralmente mais detectáveis do que aqueles sem DOIs.
À medida que finalizamos nossa análise, estamos compartilhando alguns resultados iniciais [2] e solicitando contribuições de nossa comunidade. Que lições relevantes podemos extrair deste exercício? Que mudanças as editoras de livros podem considerar com base nos resultados deste estudo?

Antecedentes do estudo
Este estudo foi projetado para avaliar os impactos e benefícios dos metadados para os usuários. Dada a sua popularidade com uma série de partes interessadas em nosso setor, nos propusemos a medir os impactos dos metadados na capacidade de descoberta na web convencional – ou seja, o Google Acadêmico ou Google Scholar (em inglês).
Nosso método de teste e rubrica de análise foram desenvolvidos com base em nossa própria pesquisa de usuários de informações, em particular como os leitores pesquisam e recuperam e-books acadêmicos, bem como estudos publicados sobre experiências de informações acadêmicas e práticas de pesquisa. Classificamos o desempenho de pesquisa de mais de 100 livros acadêmicos usando consultas de teste predefinidas (duas para cada título). Os livros testados neste estudo vieram de editoras de todos os tipos e tamanhos e representam monografias e volumes editados de uma variedade de campos; alguns eram de acesso aberto e outros foram publicados sob modelos de licenciamento tradicionais.
Desenvolvemos e executamos pesquisas de teste de itens conhecidos que foram projetadas para simular práticas comuns de pesquisadores. A análise heurística dos resultados da pesquisa foi usada para avaliar o desempenho da pesquisa em uma rubrica de pontuação de 5 pontos, projetada para medir o grau de atrito na localização do livro em questão. Esse método nos permitiu avaliar atributos específicos de livro e metadados por suas pontuações de desempenho de pesquisa para avaliar o impacto dos metadados do livro na descoberta de conteúdo no Google Acadêmico.

Resultados e descobertas
Neste estudo, aprendemos que os campos de alto valor incluem o título principal emparelhado com subtítulos, sobrenomes do autor/editor e/ou área de estudo. As consultas usando títulos completos de livros tiveram o melhor desempenho em todos os aspectos. Aqueles que usaram datas de publicação e/ou sobrenomes de autores/editores e/ou nomes de editoras, mas sem o título do livro, tiveram o pior desempenho.
Surpreendentemente, nossas pontuações de descoberta não mostram variação significativa no desempenho por tipo de livro, editado ou escrito. Os títulos de acesso aberto tiveram um desempenho um pouco melhor do que os tradicionais. Os livros que cobrem as áreas de humanidades e ciências sociais tiveram um desempenho um pouco melhor do que os livros STM, mas apenas por uma pequena diferença (que não é estatisticamente significativa).
Testamos principalmente a capacidade de descoberta de títulos de livros, a partir de números iguais de livros com e sem DOIs em nível de capítulo. Fizemos testes semelhantes para descobrir o título do capítulo, mas descobrimos que a maioria das consultas de teste para capítulos leva os usuários ao próprio livro completo. Embora os livros sem DOIs no nível do título sejam menos detectáveis, não encontramos uma diferença mensurável entre os livros com ou sem DOIs no nível do capítulo. (Observação: todos os livros neste estudo com DOIs atribuídos em nível de capítulo também carregavam um DOI em nível de título, o que foi considerado bastante comum.)
Com base nesses resultados, estamos desenvolvendo uma teoria de que livros com DOIs têm melhor desempenho no Google Acadêmico porque se beneficiam dos metadados abertos e estruturados associados a esses DOIs – que são usados por centenas de plataformas e serviços e, portanto, são “semeados” em todo o mundo. a web convencional, que o Scholar pode usar para indexação, vinculação, etc. Dito isso, no entanto, esses resultados também sugerem que os editores são mais bem atendidos por uma estratégia de metadados que esteja bem sintonizada com os protocolos esperados de cada canal para pesquisa e descoberta de livros . Em uma conversa recente sobre nossas descobertas, o próprio Anurag Acharya observou que esses resultados ressaltam a necessidade de os editores investirem na construção robusta e na ampla distribuição de metadados de livros.
Neste estudo, observamos que os protocolos de metadados em torno do Google Scholar não estão totalmente integrados aos órgãos de padrões de informações acadêmicas estabelecidos em nosso setor, como NISO, ou organizações de infraestrutura, como Crossref. Embora alguns padrões de dados convencionais prevaleçam no índice Scholar, como o uso de schema.org e HTTP, alguns atributos de metadados importantes parecem estar faltando. Por exemplo, um indicador do tipo de livro acadêmico (monografia, manual, etc.) melhoraria o índice de pesquisa do Google Acadêmico e poderia ser usado para filtrar os resultados da pesquisa, melhorando assim a experiência dos usuários na descoberta de livros acadêmicos. Um claro desafio para as editoras de livros hoje é o fato de que o Google Scholar opera fora de nossa infraestrutura de informação acadêmica governada pela comunidade.

O que vem depois
Embora este estudo tenha se concentrado no Google Scholar, os resultados e as lições aprendidas são aplicáveis a outros canais convencionais de busca/descoberta de informações. Nosso relatório, previsto para a primavera de 2023, contribuirá para a literatura destinada a apoiar o design de sistemas de informação centrados no usuário e a arquitetura de conteúdo por editores acadêmicos e provedores de serviços.
À medida que escrevemos nossas descobertas, pretendemos desenvolver uma estrutura que possa ajudar os editores e outros a medir o impacto de seu trabalho para enriquecer e distribuir metadados acadêmicos. Esperamos que esta primeira revisão sistemática dos impactos dos metadados na descoberta de livros no Google Acadêmico forneça informações valiosas para esta comunidade. Enquanto isso, compartilhe seus pensamentos e perguntas nos comentários abaixo – ou entre em contato conosco diretamente.
Os autores gostariam de agradecer a Jennifer Kemp, da Crossref, pela inspiração para mergulhar na literatura de metadados e refletir sobre seu impacto nas experiências de informações de pesquisa. Agradecimentos especiais a Anurag Acharya do Google Scholar por sua consulta durante este estudo.
== REFERÊNCIA ==
[1] CONRAD, Lettie Y; URBERG, Michelle. Measuring Metadata Impacts: Books Discoverability in Google Scholar. The Scholary Kitchen Blog, Jan. 17th 2023. Disponível em: https://scholarlykitchen.sspnet.org/2023/01/17/measuring-metadata-impacts-books-discoverability-in-google-scholar Acesso em: 18 jan. 2023.
[2] CONRAD, Lettie Y; URBERG, Michelle. With or Without: Measuring Impacts of Books Metadata. Crossref Blog, Oct. 22th 2023. Disponível em: https://community.crossref.org/t/with-or-without-measuring-impacts-of-books-metadata/3058 Acesso em: 18 jan. 2023.
-
Pesquisa une Brasil e Portugal para estudar padrões de serviços de aprendizagem em Bibliotecas

As bibliotecas do Ensino Superior devem atender às necessidades de informação da sua comunidade, onde quer que esta se encontre. Este princípio do direito de acesso é aplicado no contexto da aprendizagem a distância e está subjacente às orientações emanadas pelos Standards for Distance Learning Library Services (ACRL, 2016).
Baseado nesse documento, o presente estudo visa analisar as ações e estratégias que forma e estão sendo sendo desenvolvidas pelas bibliotecas do ensino superior para apoiar a aprendizagem à distância, durante e após a pandemia da Covid-19. Estão sendo investigadas bibliotecas universitárias de Portugal e Brasil, sob a responsabilidade das pesquisadoras:
Luiza Baptista Melo
CIDEHUS, Centro Interdisciplinar de História, Culturas e Sociedades, Universidade de Évora Portugal
Faculdade de Medicina Dentária, Universidade de Lisboa, Portugal
Tatiana Sanches
UIDEF, Instituto de Educação, Universidade de Lisboa, Portugal
APPsy, ISPA – Instituto Universitário, Lisboa, Portugal
Maria Imaculada Cardoso Sampaio
Universidade de São Paulo
Adriana Cybele Ferrari
Universidade de São Paulo
Vice-Presidenta da Federação Brasileira de Associações de Bibliotecários, Cientistas da Informação e Instituições (FEBAB).
Segue o link para acesso ao questionário: https://forms.gle/HFRbEw2LoR2FstJ38
Solicitamos a gentileza de responder às perguntas até o dia 20 de fevereiro de 2023.
Muito obrigada pela colaboração!
-
24/01 – 13h | Webinar OCLC “Redefinindo a experiência da biblioteca: colocando ideias em ação”
 Webinar Redefining the library experience: Putting ideas into action será realizado no dia 24 de janeiro de 2023 das 13h às 14h
Webinar Redefining the library experience: Putting ideas into action será realizado no dia 24 de janeiro de 2023 das 13h às 14hJunte-se a Lesley Langa, Cientista de Pesquisa Associada, Pesquisa da OCLC e líderes de bibliotecas do Conselho Global da OCLC para uma discussão sobre como as bibliotecas de todo o mundo estão repensando a experiência da biblioteca.
Junte-se a Lesley Langa, Cientista de Pesquisa Associada, Pesquisa da OCLC e líderes de bibliotecas do Conselho Global da OCLC para uma discussão sobre como as bibliotecas de todo o mundo estão repensando a experiência da biblioteca. Ouça diretamente dos líderes das bibliotecas como eles estão criando experiências inovadoras que proporcionam engajamento significativo, trazendo mudanças impactantes para as comunidades que atendem.
Apresentada pela presidente do Conselho Global da OCLC, Evi Tramantza, esta sessão será realizada dia 24/01/2023 às 13h (BRT) e incluirá discussões ativas e oportunidades para todos participarem. O evento será proferido em inglês. REGISTRE-SE PARA PARTICIPAR
Os palestrantes incluem:
- Theo Kemperman , Diretor, Bibliotheek Rotterdam, Rotterdam, Holanda
- Linda Kopecky, Reitora Associada, Bibliotecas Universitárias, Universidade de Nevada, Reno, Nevada, Estados Unidos
- Lesley Langa , Pesquisadora Associada, Pesquisa OCLC, Dublin, Ohio, Estados Unidos
- Tricia Lawrence Powell , Diretora de Serviços ao Usuário e Conservação, Biblioteca Nacional da Jamaica, Kingston, Jamaica
- Evi Tramantza , Diretora de Bibliotecas e Arquivos, Anatolia College, Thessaloniki, Grécia
O Conselho Global está hospedando este webinar para promover o diálogo entre os líderes de bibliotecas sobre a experiência de biblioteca em constante evolução. Faz parte da série Transformative Leaders da OCLC.
Saiba mais sobre a área de foco do Conselho Global de 2023: Redefinindo a experiência da biblioteca.
-
Onde estão localizadas as universidades mais bem classificadas no Ranking SCImago 2022
O SCImago Institutions Rankings (SIR) é uma classificação de instituições acadêmicas e relacionadas à pesquisa classificadas por um indicador composto que combina três conjuntos diferentes de indicadores com base no desempenho da pesquisa, resultados de inovação e impacto social medidos por sua visibilidade na web.
Ele fornece uma interface amigável que permite a visualização de qualquer classificação personalizada a partir da combinação desses três conjuntos de indicadores. Adicionalmente, é possível comparar as tendências de indicadores individuais de até seis instituições. Para cada grande setor também é possível obter gráficos de distribuição dos diferentes indicadores.
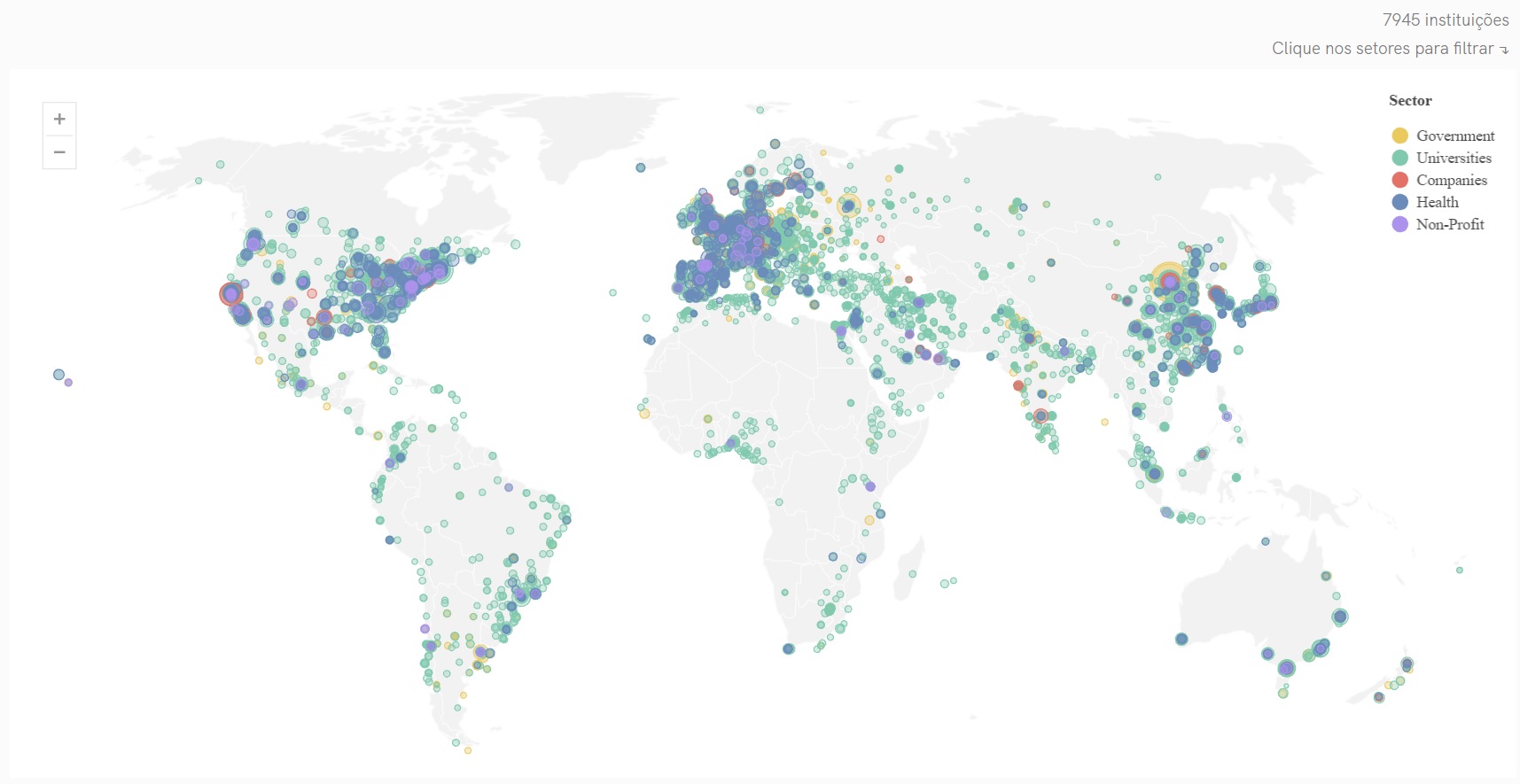
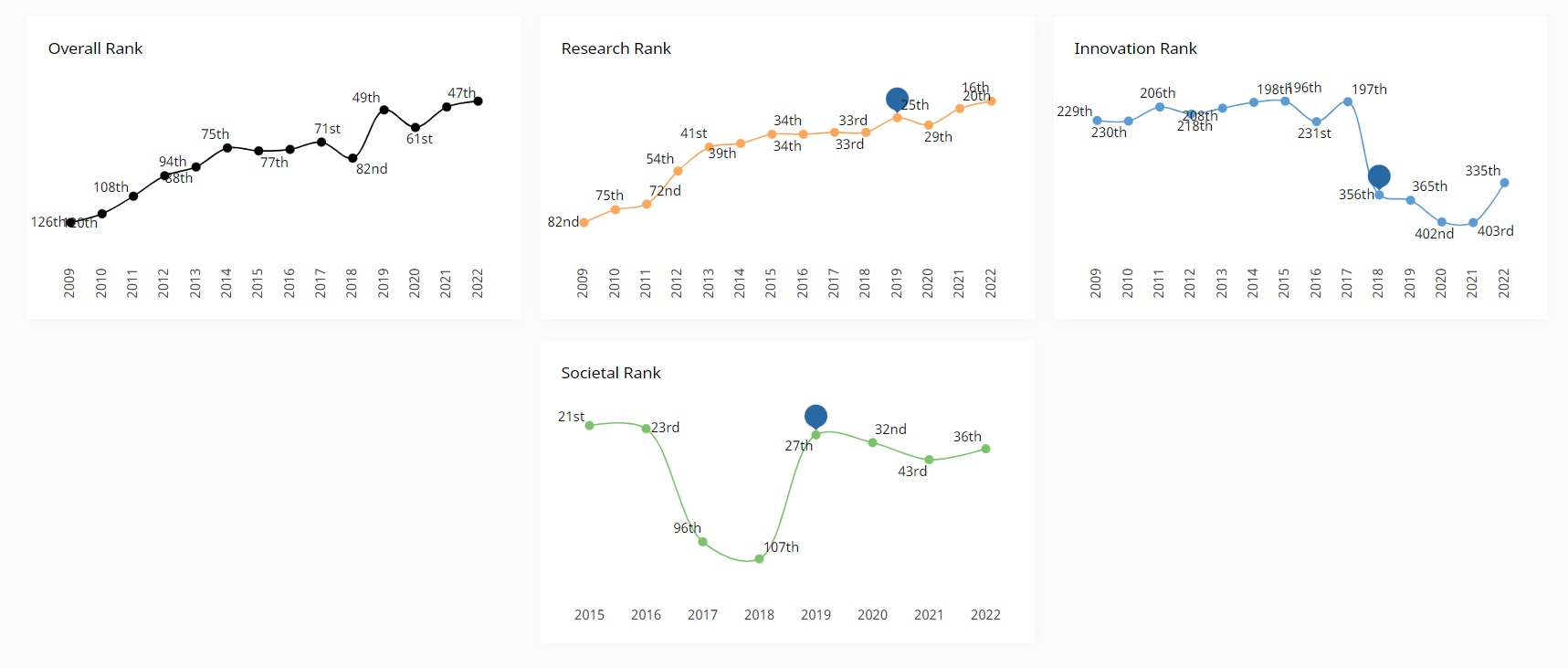
A representação geográfica das instituições elaborada pelo SCImago é uma classificação extremamente útil para conhecer o esforço no desenvolvimento científico dos países e regiões, e a presença e impacto de diferentes setores na produção científica.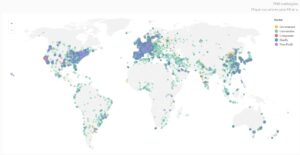 Clique sobre a imagem para melhor visualização ou confira no link: https://www.scimagoir.com/institutionsmap.phpO número de universidades e instituições de pesquisa por país ajuda a reconhecer a diferença na capacidade de geração de conhecimento científico, considerando que esta é uma dimensão de análise, assim como o desempenho obtido.Por exemplo, os Estados Unidos estão representados por 1.028 instituições, enquanto o Brasil está representado por 205 instituições apenas. No mundo, SCImago classificou 7.945 instituições. A Universidade de São Paulo encontra-se em 43º no âmbito geral da classificação.
Clique sobre a imagem para melhor visualização ou confira no link: https://www.scimagoir.com/institutionsmap.phpO número de universidades e instituições de pesquisa por país ajuda a reconhecer a diferença na capacidade de geração de conhecimento científico, considerando que esta é uma dimensão de análise, assim como o desempenho obtido.Por exemplo, os Estados Unidos estão representados por 1.028 instituições, enquanto o Brasil está representado por 205 instituições apenas. No mundo, SCImago classificou 7.945 instituições. A Universidade de São Paulo encontra-se em 43º no âmbito geral da classificação.Evolução da instituição
Os dados a seguir dão uma visão rápida sobre o desempenho científico nos últimos anos. O ranking de pesquisa refere-se ao volume, impacto e qualidade da produção de pesquisa da instituição. O ranking de inovação é calculado sobre o número de pedidos de patente da instituição e as citações que sua produção de pesquisa recebe de patentes. Por fim, o ranking societal é baseado no número de páginas do site da instituição e no número de backlinks e menções nas redes sociais.
Clique sobre a imagem para melhor visualização ou confira no link: https://www.scimagoir.com/institution.php?idp=773
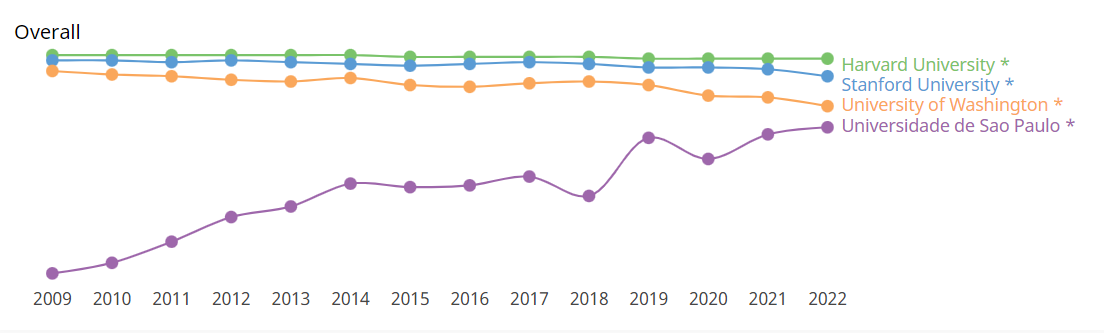
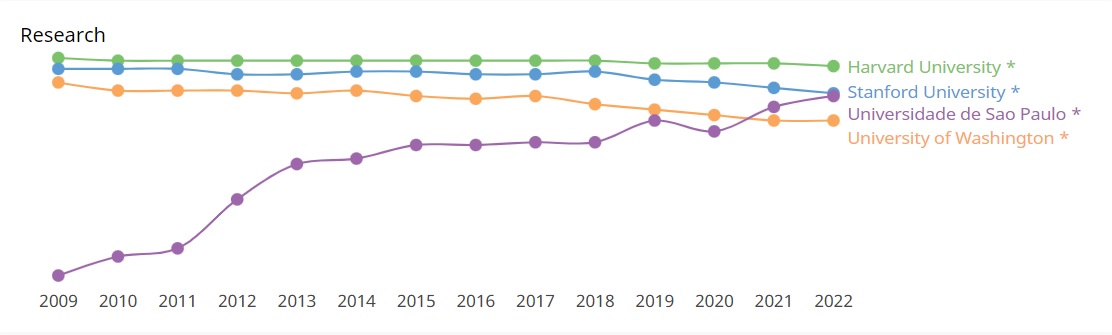
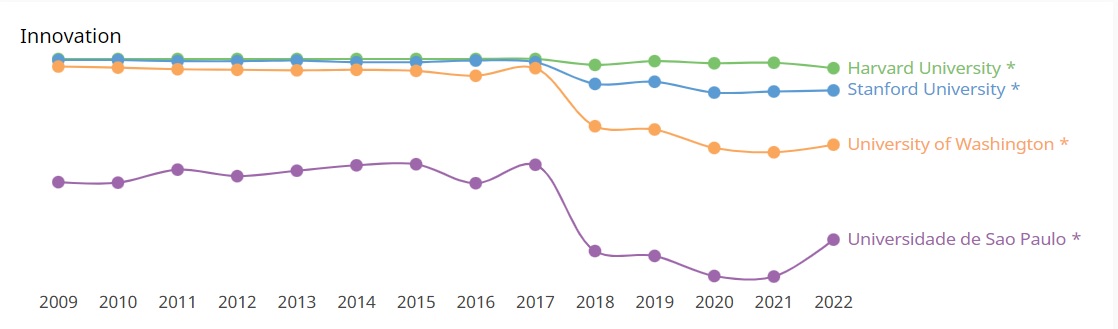
Comparação de desempenho com universidades selecionadas
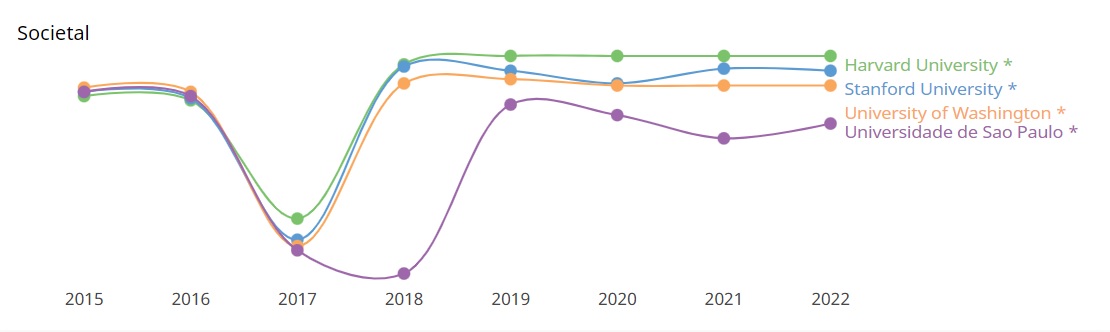
Os dados a seguir dão uma visão comparativa sobre o desempenho científico nos últimos anos entre quatro instituições: Harvard University, Stanford University, University of Whashington e Universidade de São Paulo. O ranking de pesquisa refere-se ao volume, impacto e qualidade da produção de pesquisa da instituição. O ranking de inovação é calculado sobre o número de pedidos de patente da instituição e as citações que sua produção de pesquisa recebe de patentes. Por fim, o ranking societal é baseado no número de páginas do site da instituição e no número de backlinks e menções nas redes sociais.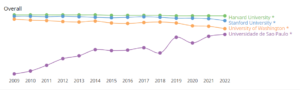
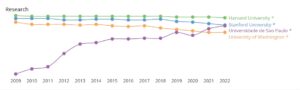
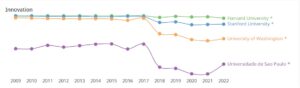

Clique sobre a imagem para melhor visualização ou confira no link: https://www.scimagoir.com/compare.php?idps[]=13590&idps[]=15199&idps[]=15488&idps[]=773
Perfil de publicação
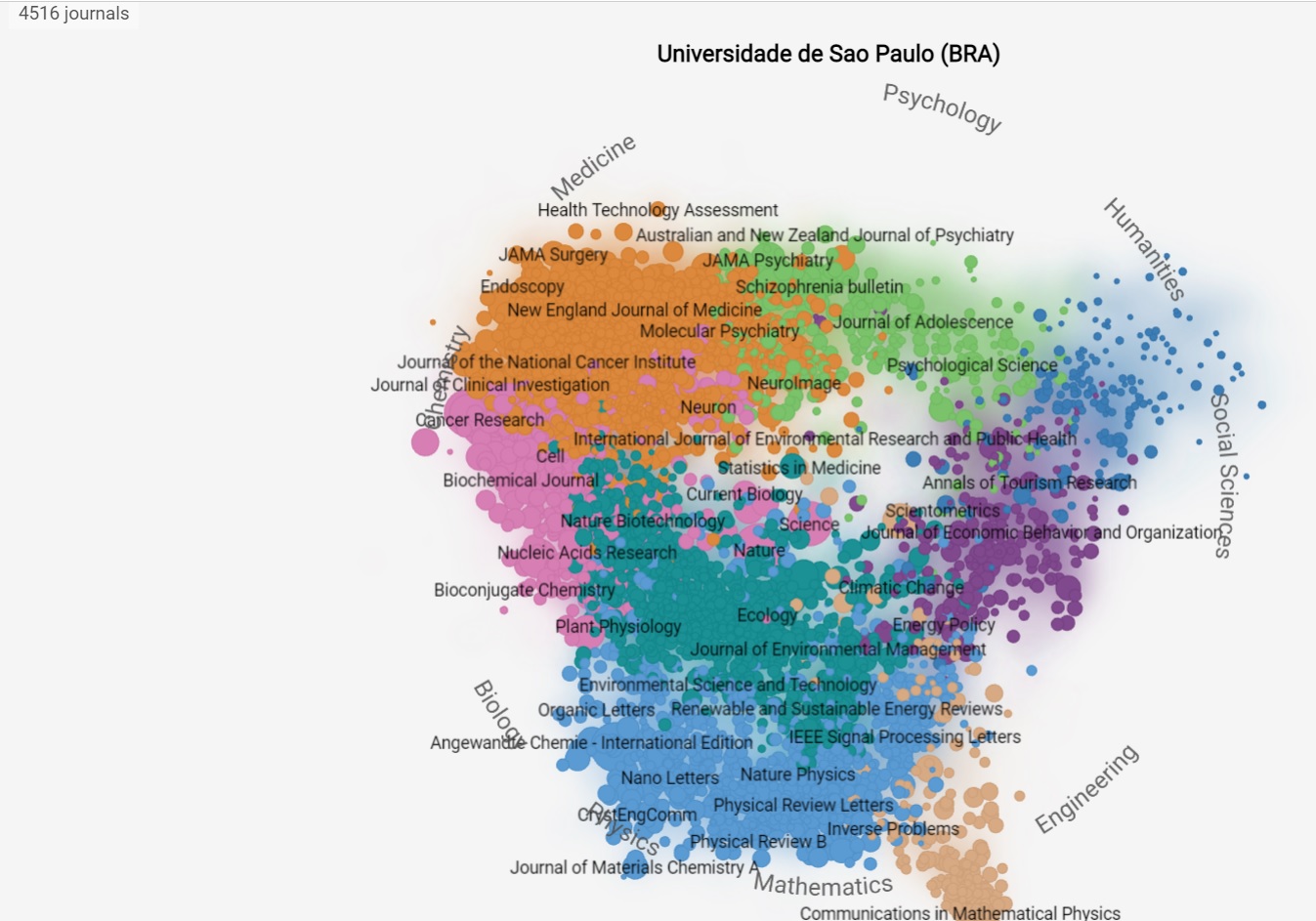
Essas são as revistas utilizadas pelos pesquisadores da instituição para publicar seus trabalhos no último ano. O tamanho de cada círculo representa o valor do SJR da publicação, e sua posição espacial representa seu assunto. Esta visualização permite identificar as áreas de conhecimento onde a instituição publicou, reconhecer o prestígio das revistas científicas nas quais o conhecimento da instituição foi publicado e identificar as comunidades científicas predominantes.
Clique sobre a imagem para melhor visualização ou confira no link: https://www.scimagoir.com/institution.php?idp=773
== METODOLOGIA ==
Para fins comparativos, o valor do indicador composto foi definido em uma escala de 0 a 100. No entanto, os gráficos de linha e os gráficos de barra sempre representam classificações (menor é melhor, portanto os valores mais altos são os piores).
Padronização do SCImago: Para alcançar o maior nível de precisão para os diferentes indicadores, foi realizado um extenso processo manual de desambiguação dos nomes das instituições. O desenvolvimento de uma ferramenta de avaliação para análise bibliométrica destinada a caracterizar as instituições de pesquisa envolve uma enorme tarefa de processamento de dados relacionados à identificação e desambiguação das instituições por meio da filiação institucional dos documentos incluídos no Scopus. O objetivo do SCImago, a este respeito, é duplo:
- Definição e identificação única de instituições: A elaboração de uma lista de instituições de pesquisa onde cada instituição é corretamente identificada e definida. Problemas típicos nesta tarefa incluem fusão ou segregação de instituições e mudanças de denominação.
- Atribuição de publicações e citações a cada instituição. Levamos em consideração a afiliação institucional de cada autor no campo ‘afiliação’ da base de dados. Desenvolvemos um sistema misto (manual e automático) para atribuição de filiações a uma ou mais instituições, conforme o caso. Assim como a identificação de vários documentos com o mesmo DOI e/ou título.
O rigor na identificação das filiações institucionais é um dos valores fundamentais do processo de normalização garantido, em qualquer caso, os mais elevados níveis de desambiguação possíveis. As instituições podem ser agrupadas pelos países aos quais pertencem. Instituições multinacionais (MUL) que não podem ser atribuídas a nenhum país também foram incluídas. As instituições marcadas com um asterisco consistem em um grupo de sub-instituições, identificadas por com o nome abreviado da instituição-mãe. As instituições-mãe apresentam os resultados de todas as suas sub-instituições. As instituições também podem ser agrupadas por setores (Universidades, Saúde, Governo,… ).
Para efeito do ranking, o cálculo é gerado anualmente a partir dos resultados obtidos em um período de cinco anos encerrado dois anos antes da edição do ranking. Por exemplo, se o ano de publicação selecionado for 2021, os resultados utilizados são os do período de cinco anos 2015-2019. A única exceção é o caso dos indicadores web que foram calculados apenas para o último ano.
O critério de inclusão é que as instituições tenham publicado pelo menos 100 trabalhos incluídos na base de dados SCOPUS durante o último ano do período selecionado. A fonte de informação utilizada para os indicadores de inovação é a base de dados PATSTAT. As fontes de informação utilizadas para os indicadores de visibilidade na web são Google e Ahrefs. O banco de dados Unpaywall é usado para identificar documentos de acesso aberto. Altmetrics de métricas PlumX e Mendeley são usadas para DETERMINAR O Fator Social.
A SIR é a partir de agora uma LEAGUE TABLE. O objetivo do SIR é fornecer uma ferramenta métrica útil para instituições, formuladores de políticas e gerentes de pesquisa para análise, avaliação e melhoria de suas atividades, produtos e resultados. O Melhor Quartil é obtido pela instituição em seu país comparando os quartis com base no indicador geral, fator de pesquisa, fator de inovação e fator societal.
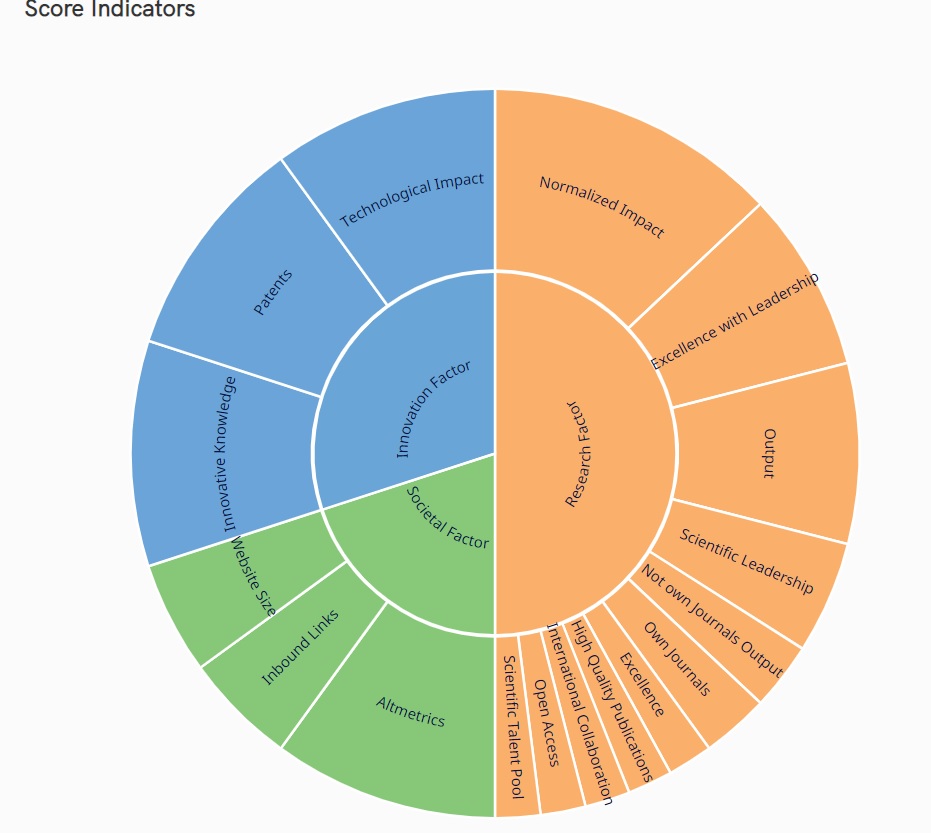
== Indicadores ==
Os indicadores são divididos em três grupos destinados a refletir as características científicas, econômicas e sociais das instituições. O SIR inclui indicadores dependentes e independentes do tamanho; ou seja, indicadores influenciados e não influenciados pelo tamanho das instituições. Dessa forma, o SIR fornece estatísticas gerais da publicação científica e demais produções das instituições, ao mesmo tempo em que permite comparações entre instituições de diferentes portes. Deve-se ter em mente que, uma vez calculado o indicador final a partir da combinação dos diferentes indicadores (aos quais foi atribuído um peso diferente), os valores resultantes foram normalizados em uma escala de 0 a 100.
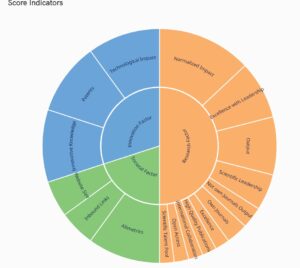

Pesquisa:
- Impacto Normalizado (Saída de Liderança) (NI) : O Impacto Normalizado é calculado sobre a saída de liderança da instituição usando a metodologia estabelecida pelo Karolinska Institutet na Suécia, onde é denominado “Média de pontuação de citação normalizada de campo orientado por item”. A normalização dos valores de citação é feita em nível de artigo individual. Os valores (em números decimais) mostram a relação entre o impacto científico médio de uma instituição e a média mundial definida com uma pontuação de 1, –ou seja, uma pontuação NI de 0,8 significa que a instituição é citada 20% abaixo da média mundial e 1,3 significa que a instituição é citado 30% acima da média (Rehn e Kronman, 2008; González-Pereira, Guerrero-Bote e Moya-Anegón, 2011; Guerrero-Bote e Moya-Anegón, 2012). Indicador independente de tamanho.
- Excelência com Liderança ( EwL ) : Excelência com Liderança indica a quantidade de documentos em Excelência em que a instituição é o principal contribuidor (Moya-Anegón, et al., 2013). Indicador dependente do tamanho.
- Output (O) : número total de documentos publicados em revistas científicas indexadas no Scopus (Romo-Fernández, et al., 2011; OCDE, 2016). Indicador dependente do tamanho.
- Saída de Periódicos Não Próprios (NotOJ) : número de documentos não publicados em periódicos próprios (publicados pela instituição). Indicador dependente do tamanho. Adicionado na edição de 2019.
- Periódicos Próprios (JO) : número de periódicos publicados pela instituição (serviços de edição). Indicador dependente do tamanho. Adicionado na edição de 2019.
- Colaboração Internacional ( IC ) : Produção da instituição produzida em colaboração com instituições estrangeiras. Os valores são calculados analisando a produção de uma instituição cujas afiliações incluem mais de um endereço de país (Guerrero-Bote, Olmeda-Gómez e Moya-Anegón, 2013; Lancho-Barrantes, Guerrero-Bote e Moya-Anegón, 2013; Lancho-Barrantes, et al., 2013; Chinchilla-Rodríguez, et al., 2010; 2012). Indicador dependente do tamanho.
- Publicações de alta qualidade (Q1) : o número de publicações que uma instituição publica nas revistas acadêmicas mais influentes do mundo. Estes são aqueles classificados no primeiro quartil (25%) em suas categorias, conforme ordenado pelo indicador SCImago Journal Rank (SJRII) (Miguel, Chinchilla-Rodríguez e Moya-Anegón, 2011; Chinchilla-Rodríguez, Miguel e Moya-Anegón, 2015 ). Indicador dependente do tamanho.
- Excelência ( Exc ) : Excelência indica a quantidade de produção científica de uma instituição que está incluída entre os 10% dos artigos mais citados em suas respectivas áreas científicas. É uma medida da produção de alta qualidade das instituições de pesquisa (SCImago Lab, 2011; Bornmann, Moya-Anegón e Leydesdorff, 2012; Bornmann e Moya-Anegón, 2014a; Bornmann et al., 2014b). Indicador dependente do tamanho.
- Liderança Científica (L) : Liderança indica a quantidade de produção de uma instituição como contribuinte principal, ou seja, a quantidade de artigos em que o autor correspondente pertence à instituição (Moya-Anegón, 2012; Moya-Anegón et. al, 2013; Moya-Anegón, et al.,). Indicador dependente do tamanho.
- Open Access (OA) : porcentagem de documentos publicados em periódicos Open Access ou indexados no banco de dados Unpaywall. Indicador independente de tamanho. Adicionado na edição de 2019.
- Scientific Talent Pool (STP) : número total de diferentes autores de uma instituição na produção total de publicações dessa instituição durante um determinado período de tempo. Indicador dependente do tamanho.
Inovação:
- Conhecimento Inovador (IK) : saída de publicação científica de uma instituição citada em patentes. Baseado em PATSTAT (http://www.epo.org) (Moya-Anegón e Chinchilla-Rodríguez, 2015). Dependente do tamanho.
- Impacto Tecnológico (TI) : percentual da produção de publicações científicas citadas em patentes. Esse percentual é calculado considerando a produção total nas áreas citadas em patentes, que são as seguintes: Ciências Agrárias e Biológicas; Bioquímica, Genética e Biologia Molecular; Engenheiro químico; Química; Ciência da Computação; Ciências da Terra e Planetárias; Energia; Engenharia; Ciência ambiental; Profissões de Saúde; Imunologia e Microbiologia; Ciência de materiais; Matemática; Medicamento; Multidisciplinar; Neurociência; Enfermagem; Farmacologia, Toxicologia e Farmacêutica; Física e Astronomia; Ciências Sociais; Veterinária . Baseado em PATSTAT (http://www.epo.org) (Moya-Anegón e Chinchilla-Rodríguez, 2015). Independente de tamanho.
- Patentes (PT) : número de pedidos de patente (famílias simples). Baseado em PATSTAT (http://www.epo.org). Dependente do tamanho.
Impacto social:
- Altmetrics (AM) : O indicador Altmetrics foi calculado sobre os 10% dos documentos das instituições (melhores documentos em relação ao valor de impacto normalizado). Este indicador tem dois componentes:
- PlumX Metrics (peso: 70%): número de documentos que possuem mais de uma menção no PlumX Metrics (https://plumanalytics.com). Consideramos menções no Twitter, Facebook, blogs, notícias e comentários (Reddit, Slideshare, Vimeo ou YouTube)
- Mendeley (peso: 30%): número de documentos que possuem mais de um leitor no Mendeley (https://www.mendeley.com).
Este indicador depende do tamanho. Adicionado na edição de 2019.
- Número de Backlinks (BN) : número de redes (sub-redes) de onde vieram os links de entrada para o site da instituição. Dados extraídos do banco de dados Ahrefs (https://ahrefs.com). Dependente do tamanho.
- Tamanho da Web (WS) : número de páginas associadas ao URL da instituição de acordo com o Google (https://www.google.com) (Aguillo et al., 2010). Dependente do tamanho.
== REFERÊNCIA ==
SCIMAGO INSTITUTIONS RANKING. 2022. Disponível em: https://www.scimagoir.com/ Acesso em 29 dez. 2022.








Fim da página, você pode ver: